Estimators; An easy way to work with Tensorflow
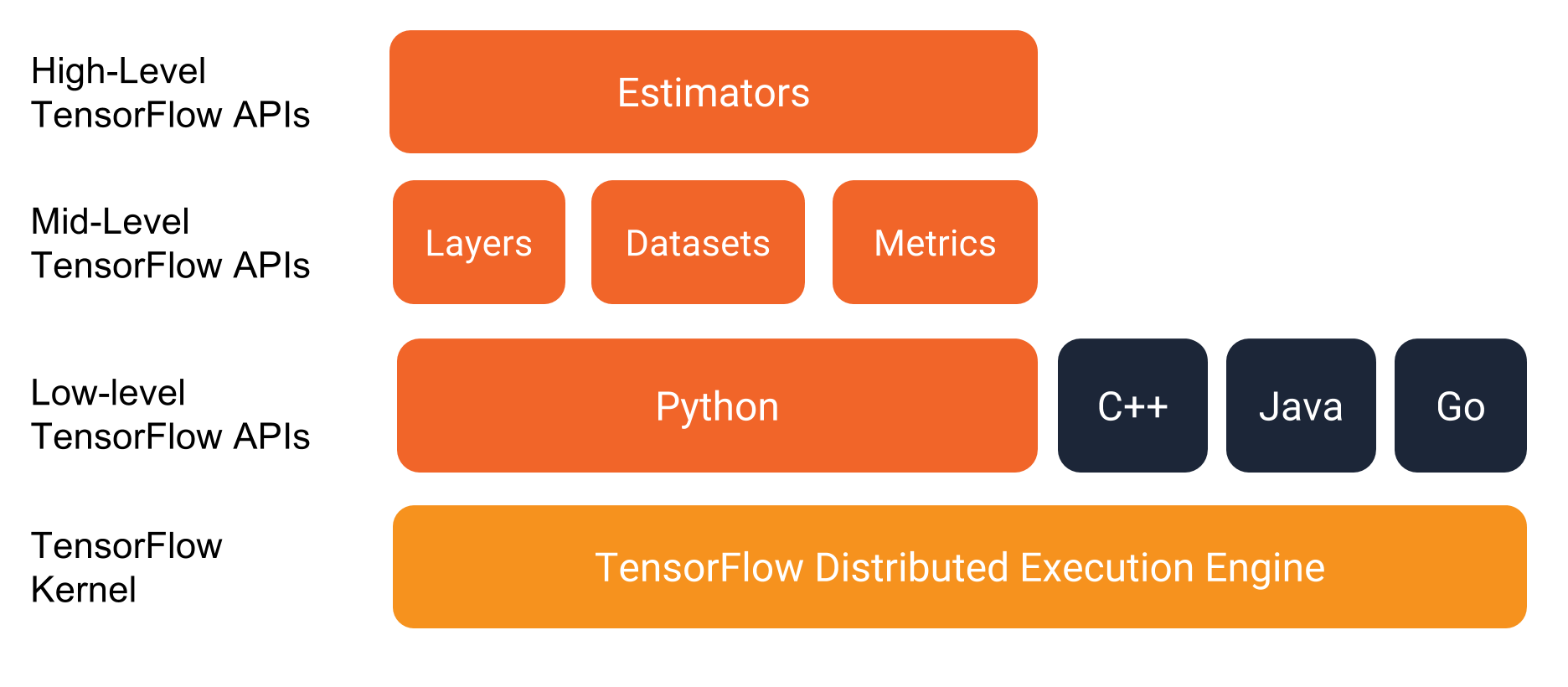
In a previous post, we discussed about Tensorflow graphs and sessions. Since building a computation graph, worrying about sessions too much and unnecessary work, Tensorflow comes with this high level API called Estimators it is inspired by scikit-learn and simplify machine learning programming. It doesn’t just add an abstraction to graphs and sessions but it also encapsulate the actions like training, evaluation, prediction and export for serving with Google CloudML it handles scaling, and running on different hardware out of the box. Besides, Tensorflow official documentation highly encourage to use Estimator API in production level developments. One other benefit of using Estimators is that it already has canned estimators which are pre made to handle various different ML problems. However, not all the ML problems can be solved with the give pre built Estimators therefore Tensorflow has an easy API to implement custom estimators. It’s pretty easy to even create keras models and wrap them around with estimator functionalities to get all the power of estimators to it.
Let’s see how to build a model with a pre-made estimator.
In this post just for the purpose of showing how to build a model with Estimators we will be using 2016 Green Taxi trip data from NYC OpenData portal. In this post we will not worry about model accuracy or the real problem this is just to show how to use estimator API and how to run such pipeline.
import pandas as pd
from sodapy import Socrata
client = Socrata("data.cityofnewyork.us", None)
results = client.get("pqfs-mqru", limit=10000)
results_df = pd.DataFrame.from_records(results)
Here we have read data from NYC OpenData portal to a Pandas dataframe. Since the dataset is quite big we will just limit the number of rows to 10,000 (it has 1.3 million rows but for the purpose of this post we don’t need the entire dataset). Keep in mind that you may need to pip install sodapy before executing above code.
Let’s prepare our data.
We are going to predict the fare amount for a taxi ride given pickup longitude and latitude,’drop off longitude and latitude and passenger count. pretty simple!
First we need to identify our feature columns and label columns, then split the dataset randomly to two parts one is for training and the other is for validation.
import numpy as np
CSV_COLUMNS = ['dropoff_latitude', 'dropoff_longitude','pickup_latitude','pickup_longitude','passenger_count', 'fare_amount']
FEATURES = CSV_COLUMNS[0:len(CSV_COLUMNS) - 1]
LABEL = CSV_COLUMNS[-1]
# Split into train and eval as 80% and 20% respectively.
np.random.seed(seed=1) # makes split reproducible
msk = np.random.rand(len(results_df)) < 0.8
df_train = results_df[msk]
df_valid = results_df[~msk]
Then we need input functions to read the pandas dataframe.
def make_input_fn(df, num_epochs):
return tf.estimator.inputs.pandas_input_fn(
x = df[FEATURES].astype(float),
y = df[LABEL].astype(float),
batch_size = 128,
num_epochs = num_epochs,
shuffle = True,
queue_capacity = 1000,
num_threads = 1
)
Our input function for predictions is the same except we don’t provide a label and number of epochs are 1.
def make_prediction_input_fn(df):
return tf.estimator.inputs.pandas_input_fn(
x = df[FEATURES].astype(float),
y = None,
batch_size = 128,
num_epochs = 1,
shuffle = True,
queue_capacity = 1000,
num_threads = 1
)
Now we have prepared our data and created input functions for both training and validation data. For huge datasets which cannot be accommodated in system memory you can use Dataset API but that’s beyond the scope of this post.
Next we create feature columns. In this particular problem we have longitudes, latitudes and number of passengers all are numerical.
def make_feature_cols():
input_columns = [tf.feature_column.numeric_column(k) for k in FEATURES]
return input_columns
Let’s use a very simple DNNRegressor which is a pre made Estimator with the inputs and feature columns which we created in the above functions.
import shutil
import tensorflow as tf
tf.logging.set_verbosity(tf.logging.INFO)
OUTDIR = 'taxi_trained'
shutil.rmtree(OUTDIR, ignore_errors = True) # start fresh each time
model = tf.estimator.DNNRegressor(hidden_units = [32, 8, 2],
feature_columns = make_feature_cols(), model_dir = OUTDIR)
model.train(input_fn = make_input_fn(df_train, num_epochs = 100))
After training the model let’s evaluate on the validation data
def print_rmse(model, name, df):
metrics = model.evaluate(input_fn = make_input_fn(df, 1))
print('RMSE on {} dataset = {}'.format(name, np.sqrt(metrics['average_loss'])))
print_rmse(model, 'validation', df_valid)
As you can see the results are not very good. It needs more fine tuning and probably some feature engineering. However, This is just to show how the tensorflow code is written for estimators. Hope this will help in starting with Tensorflow Estimators. Happy “Estimating”.
Thanks!